JDK-HashMap解析
jdk 类介绍
HashMap 是一个继承Map接口并且是使用哈希表的实现。提供了所有的map操作,并且允许null建和null值。除了非同步方式和允许null键值,它大致上可以等同于Hashtable。影响HashMap表现的有两个原因:初始容量和加载因子。
capacity:容量指的是hash表中的总容量。初始容量在第一次创建hashmap的时候就已经创建好了。
load factor: 加载因子,是测量capacity在hash表达到了多满的时候可以自动增长。
当键值对达到了加载因子的量并且超过了当前的capacity,hash表就会重新进行hash(意思是内部数据结构将重建),目的是为了将hash表能够达到差不多两倍的容量。
通常的规则是,默认的加载因子为0.75,它可以在时间和空间上做一个非常好的平衡。如果设置自定义capacity,map里面可能存在多少键值队就需要作为一个考虑因素,以达到最小的rehash操作。如果初始capacity在设置capacity之后还能存下更多的键值对,那么就不会出现rehash操作。
如果事先能大致确认map的容量是多少,那么给map定一个初始化大小是非常可行的,会比让它自己增长更有效率。在hash表中如果出现太多的相同的key拥有相同的hashCode()会降低效率,如果需要改善这种关系,如果键是可以比较的,类可以使用key的比较顺序来进行改善。
HashMap的实现是非线程安全的。在多线程的环境下,必须在外部上进行同步控制。如果外部没有控制,那么需要将map进行包装,也就是使用Collections.synchronizedMap(map)方法,最好是在一开始创建map的时候就进行包装。
map的iterators方法是fail-fast的。在iterator创建之后,如果map的结构被修改了,除了iterator的remove方法,iterator会抛出ConcurrentModificationException异常。所以在多线程环境下进行修改,iterator会快速的返回失败。不过也得注意在非同步环境下,迭代器的fail-fast不能得到保证。迭代器抛出这个异常一个非常好的功能,但是不应该依赖它来写程序,如果出现异常那么就应该说明程序有bug。
jdk的源码里面,介绍的非常详细。真的很详细。
分块介绍
之前说过map是非线程安全的,这节就单纯的聊一下非线程安全下的map。
一个类我们从哪里来看它了?其实我也不知道,那就干脆从我们使用一个对象开始。我们是先创建对象,给对象设置值,然后使用对象的方法。
创建map
通常在创建map的时候我们会使用对象的构造方法,如果有对象有属性,可能还会有带参数的构造方法。所以在创建map之前我们先了解下map有哪些属性?
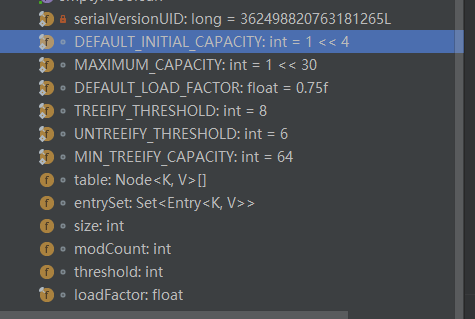
通过idea我截取了一个图,在jdk8中是
在jdk7中: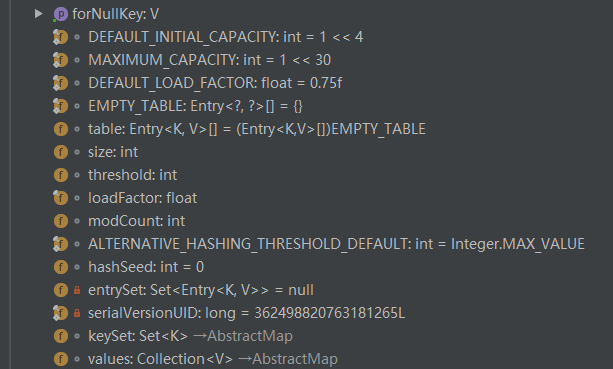
可以看到,map对象里面有一些属性,根据这些属性的定义我们可以猜到大致的意思。
DEFAULT_INITIAL_CAPCITY = 1<<4:默认容量大小,1左移4位,16。记住默认的大小必须是2的幂。MAXIMUM_CAPACITY = 1<<30:最大的容量DEFAULT_LOAD_FACTOR:加载因子,默认0.75Entry<?,?>[] EMPTY_TABLE: 空表Entry<K,V>[] table:长度为2的幂方,并且必要的时候可以改变大小,默认为空表。注意到这个字段是transientsize: 实际map中键值对的数量threshold:下一次表重构的极限值modCount:hash表结构修改一次就增加一次,包括增加减少键值对,内部数据结构重构。主要用来在迭代器中fail-fast
大致的参数就这些了。
然后我们看到构造方法,如下图:
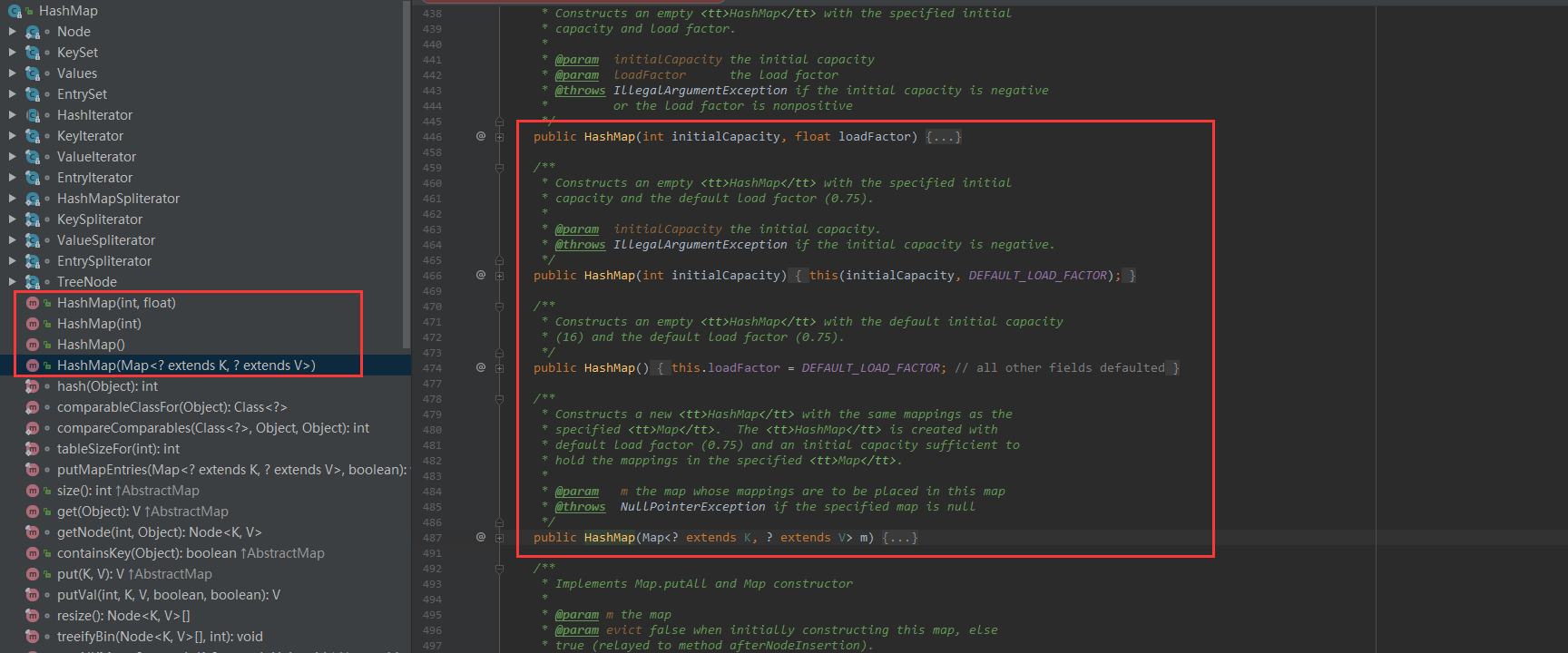
1 | public HashMap(int initialCapacity) { |
如果你看构造函数带有Map的构造方法:
1 | public HashMap(Map<? extends K, ? extends V> m) { |
你会发现,同样的它也在里面调用带两个参数的构造方法,所以我认为,这个带两个参数的构造方法可以算作是基本方法,其实想想这算不算代码复用?如果我们可以在平常的开发中开发出了基础方法,那么是否也可以像这样进行包装使用?
这三个构造方法其实只是包装了一层而已,当然map构造方法进行了一些其它的操作,所以我们需要再看下里面的基础构造方法:
1 | public HashMap(int initialCapacity, float loadFactor) { |
这里可以看到,我们的map里面,在使用的时候至少需要进行两个属性设置:initialCapacity初始容量和loadFactor加载因子。
可以看到代码的严谨性:在初始化的时候进行了参数可用性校验,平常我写方法的时候,偶尔会忘记这个,不过最后我会根据sonar扫描一次代码提交。哈哈sonar这点还是可以做到的。
在这个构造方法里面init()是一个空方法。
在map的构造方法里面后面还有两个操作,一个是inflateTable,一个是putAllForCreate。其实可以想到,用map的构造方法是有数据的,不同于其它三个,其它三个都是无数据的。所以我们只需要构建一个map出来就好了。而map的构造方法拥有数据所以在构建map之后我们需要将数据填充到新的map中。一个是扩容的代码:
1 | private static int roundUpToPowerOf2(int number) { |
之后的设置初始值就不详细说了。
常用方法
常用方法put(key,value)
这个方法是从Map接口中继承过来的,我们大致猜测一下,map如果插入了一个键值对,插入之前我们是不是需要先判断一下容量?是不是还需要有个地方存入这个值?在哪里存这个键值对?:
1 | public V put(K key, V value) { |
我们再代码中就可以看到之前的问题了,不过代码实现中还做了null值的处理。下面我们一个个来看:
扩容处理:inflateTable(threshold); 这个在上面构造map的时候讲过了。
空值处理:putForNullKey(value);
1 | private V putForNullKey(V value) { |
可以看到,这里的的操作是从0位置开始查找的。也就是从一开始遍历,这种情况下可以想到一个O(n)的时间复杂度。所以,如果是1.7,null键最好不要存在。
在代码中可以看到存键值对的地方是Entry,关于Entry我们现在只需要知道它是一个单链表的数据结构就好了,之后我们专门讲解一下Entry和hash。
讲完1.7。我们看看1.8中的put方法:
1 | public V put(K key, V value) { |
jdk1.8中的put方法,实现好像有些优化。加入了TreeNode,之后这块我补上,整体的流程是和1.7一致的。
常用方法get(key)
该方法在1.7中的实现是:
1 |
|
1.7中还是很好理解的,这里主要是hash值计算,之后我们重点讲解。
在1.8中,get方法:
1 |
|
注意到8中总是计算判断第一个node,为什么?之后了解清楚了再来详细解析
常用方法containsKey(Object),containsValue(Object)
containsKey(Object)的源码中我们可以看到也是调用了getEntry方法:
1 | public boolean containsKey(Object key) { |
containsValue(Object)的源码中我们可以看到,基本类似,也是循环链表,然后获取到值之后比较value:
1 | public boolean containsValue(Object value) { |
常用方法keySet(),values(),entrySet()
这几个方法是指代的键,值遍历,以及键值对遍历。
常用方法size(),内部方法resize()
这里就需要主要注意resize()方法是default的,也就是同一个包下面才可以调用。
size()方法就是为了获取到map里面真实的实例数量,返回的是size属性。
resize()方法在每次达到极限界值的时候会自动调用:
1 | void resize(int newCapacity) { |
Entry,hash,hashCode(),size,capacity,threshold
前面我们讲过一些常用的方法,put,get,size等,这些方法其实都是有一定关联的,put前是不是应该先判断容量是否够?不够该怎样,够该怎样。其实就是这样,就像流程图一样,只不过在具体的实现上面我们会有不同的方式。使用不同的数据结构来做优化。
这里我们需要讲一下Entry,hash,hashCode(),size,capacity,threshold他们代表的意义,以及作用。
如果说map是存储键值对,那么键是怎么存?值又是怎么存?两者怎么关联起来了?回过头我们思考这些问题,最好的方式就是看看put方法是怎么运作的:
jdk1.7:
1 | public V put(K key, V value) { |
实际上它使用的是的是Entry[] table 数组,而Entry是一个链表的形式。
1 | static class Entry<K,V> implements Map.Entry<K,V> { |
hashCode方法是一个本地方法,hash算法实在key的hashCode上计算的,这里有两篇文章,感觉很好,我就不敢多说了:
http://www.cnblogs.com/xiongpq/p/6175702.html,http://blog.csdn.net/fjse51/article/details/53811465;
size是指的map实际中存在了多少键值对,也就是实际的实例;
capacity是指这个map的总容量;
threshold是一个极限值,当达到了size达到了极限值的时候就会自动扩容(2的幂次方),threshold的计算为capacity*load factor。
在jdk8中感觉变化太大了,下次要单独讲讲jdk8。另外还需要讲解一下在多线程下的map该怎么操作。
疑问待解决
1:在put的时候,如果是重复键,再第二次的时候就只是替换了,那么entry链表有什么用?为什么这么设计?
2:hash的计算方式?hashCode计算方式,什么是hashCode?那些位运算是怎么做的?

