Docker Swarm 实践的一些经验总结
最近弄了一下Docker Swarm。在公司已经把我拉入了黑名单,因为只要我已启动docker公司的mysql就得挂。我也是好奇,正想找问题原因。服务器的密码就已经改了,我是没有机会了。不过在改密码之前,我还是获得一些宝贵的经验,这个我觉得很重要,可以记录下来,自己以后再踩坑的时候可以自己参照下。
环境准备
ubuntu机器一台,centos一台,都安装了docker。docker的版本是Docker version 17.12.0-ce, build c97c6d6。4个spring boot项目:eureka,warehouse,web,booksrv。MySQL使用的是另外一台机器上的安装在hosts(非容器化)。eureka做为注册中心,启动了两个示例。部署方式使用的docker stack。 也有直接使用了docker service。使用了网络overlay,看了网上很多文章,对于网络不太了解就用了原生的,这样方式至少容易理解。创建了overlay网络springcloud-overlay。还是用了java:8-jre-alpine镜像
做了些什么事情
实现了两台机器上的docker容器连通,U机器上的容器,能够访问C机器上的容器。这说明服务容器化是可以实现的。当然我说的是废话,google以及一系列大公司已经完成了k8s的线上实践了。不过我们还是比较小,经验不丰富,所以采用最简单的方式,先跑一下,看能否跑通,之后再说下一步。
实际过程
1. 踩的坑
一开始我是想通过在两台机器上各自暴露eureka端口,然后让eureka互相注册,而在每台机器上都启动容器服务并且注册到每台机器eureka上,这种方式理论模型如下图:
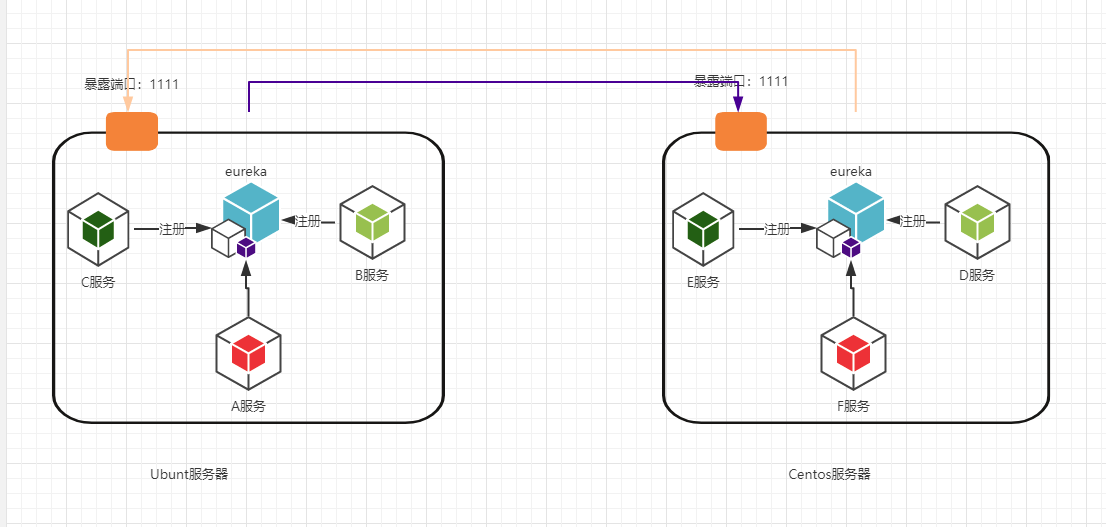
我们在eureka上是看到了这些服务都有注册到了,而且可以明显看到服务的ip地址是:172.17.0.0/16 区间的。貌似一切很正常,然后我们尝试访问服务,在每个服务日志中基本都是NO instance XXX Exception,不是在eureka已经注册了么,为什么还没有了?eureka应该是根据ip地址加端口来找服务的,这种情况下,如果A服务找到D服务,发现注册中心有注册地址ip,找到了ip地址后(不清楚这里是eureka转发,还是eureka将地址发给A,A再请求),但是根据找到的ip去请求服务,也就是在A服务上去找D的ip地址,因为D在Centos服务器上,所以根本不可能到达。那么请求又怎么可能知道了。明显两者应该在不同的。(突然感觉不对劲,如果两个eureka不能相互注册,注册中心又怎么可能启动多个。。。这里待定,感觉有问题。)再回首想一下,嗯,没问题,我们使用bridge网络的时候,是内网。没错,是内网,我们一般使用eureka都是公网,至少也是两台hosts能够相互连通,在同一个网络下。但是使用docker默认的网络是内网,A机器是无法访问B机器的172.xxx的网络的。
2. swarm方式
在网上找了一圈资料,有在阿里云找到的springcloud项目,并且使用eureka的注册方式,但是他们基于阿里云网络vpc,对于我们不合适,我们是自建机房,尽管没有运维人员去管理。阿里云的方式行不通之后,后来找到swarm,因为我想总有人有这方面(跨主机容器通信)的需求的。刚开始找到了一些是k8s,觉得学习成本有点大,我只是个小java开发,还没强大到那个地步。。。。后来发现swarm好像也可以。一想,swarm毕竟是docker自带的,学习成本应该不大,本且之前也有接触,果断就用swarm做测试。
2.1 创建overlay网络
swarm 其实管理的就是docker容器,一开始我们使用docker swarm init.然后让它称为manager,其它的docker容器只要join就可以了。这点还是很方便。
1 | docker swarm init |
这种方式就简单的构建了一个swarm了。然后我们首先创建网络。
1 | docker network create -d overlay springcloud-overlay |
2.2 准备镜像
创建网络后,就开始准备相应的镜像和Dockerfile。根据每个人的环境不同可以准备相应的Dockerfile:
eureka.Dockerfile: 主要作为注册中心用
1 | FROM java:8-jre-alpine |
booksrv.Dockerfile: 做一个无需连接数据库的服务提供者
1 | FROM java:8-jre-alpine |
warehouse.Dockerfile:连接数据库的服务提供者
1 | FROM java:8-jre-alpine |
web.Dockerfile:客户端调用booksrv和warehouse服务的接口
1 | FROM java:8-jre-alpine |
在不同的文件夹下将dockerfile文件准备好之后,我们可以使用docker build -t chenzhijun/imagename .;(chenzhijun/iamgename可以自定义)
2.3 准备yml文件
我们准备好镜像文件之后,可以使用docker stack的方式部署服务。
eureka.yml
1 | version: '3' |
service.yml
1 | version: '3' |
我们可以使用docker stack deploy -c eureka.yml(service.yml) eureka(service)。
之后可以使用docker stack ls查看启动了哪些服务,使用docker stack services eureka(service)来查看具体的信息。
这个时候,你可以使用docker ps 来看机器上启动了哪些服务,然后使用docker logs -f containerid来看输出的日志记录。
嗯基本上就可以看到相应的输出。。
docker swarm的另一种服务创建方式:
1 | docker service create --name warehouse1 \ |
一些常见的命令:
1 |
|